Lets take a look at how you can use Apache Spark to process big data. Apache Spark in Azure Synapse Analytics is one of Microsofts implementations of Apache Spark in the cloud.
![]() Apache Spark Wikipedia
Apache Spark Wikipedia
Apache Spark is a unified analytics engine for large-scale data processing.
What is apache spark. Apache Spark is a lightning-fast cluster computing technology designed for fast computation. Big data solutions are designed to handle data that is too large or complex for traditional databases. A Spark application has a driver program which runs the users main function.
It is based on Hadoop MapReduce and it extends the MapReduce model to efficiently use it for more types of computations which includes interactive queries and stream processing. Spark DataFrames can be created from various sources such as Hive tables log tables external databases or the existing RDDs. It was originally developed at UC Berkeley in 2009.
What is Apache Spark. On its website Apache Spark is explained as a fast and general e n gine for large-scale data processing. Apache Spark is an open source parallel processing framework for running large-scale data analytics applications across clustered computers.
Apache Spark is an advanced analytics engine which can easily process real-time data. Before Apache Software Foundation took possession of Spark it was under the control of University of California Berkeleys AMP Lab. Since its release Apache Spark the unified analytics engine has seen rapid adoption by enterprises across a wide range of industries.
In this part of the Spark tutorial you will learn What is Apache Spark DataFrame Spark DataFrames are the distributed collections of data organized into rows and columns. Apache Spark Spark is an open source data-processing engine for large data sets. But that doesnt even begin to encapsulate.
It can handle both batch and real-time analytics and data processing workloads. It provides high-level APIs in Java Scala Python and R and an optimized engine. Apache Spark is a general-purpose cluster computing framework.
Spark is a lighting fast computing engine designed for faster processing of large size of data. Apache Spark is an open-source distributed processing system used for big data workloads. Apache Spark is an open-source parallel processing framework that supports in-memory processing to boost the performance of applications that analyze big data.
Apache Spark is a lightning-fast unified analytics engine for big data and machine learning. Apache Spark is a lightning-fast open source data-processing engine for machine learning and AI applications backed by the largest open source community in big data. Spark can run on.
The largest open source project in data processing. Apache Spark is a data processing framework that can quickly perform processing tasks on very large data sets and can also distribute data processing tasks across multiple computers either on its. Spark is a data processing engine developed to provide faster and easy-to-use analytics than Hadoop MapReduce.
Apache Spark is a unified analytics engine for big data processing with built-in modules for streaming SQL machine learning and graph processing. But later maintained by Apache Software Foundation from 2013 till date. Apache Spark is an open-source engine for analyzing and processing big data.
What is Apache Spark. What is Apache Spark. Apache Spark is an open-source distributed cluster-computing framework.
Its also responsible for executing parallel operations in a cluster. Apache Spark is a unified analytics engine for large-scale data processing with built-in modules for SQL streaming machine learning and graph processing. It was introduced by UC Berkeleys AMP Lab in 2009 as a distributed computing system.
Apache Spark is highly efficient in iterative data processing. It is an in-memory processing framework which is efficient and much faster as compared to MapReduce. It utilizes in-memory caching and optimized query execution for.
Apache Spark is a parallel processing framework that supports in-memory processing to boost the performance of big-data analytic applications.
 Apache Spark Architecture Distributed System Architecture Explained Edureka
Apache Spark Architecture Distributed System Architecture Explained Edureka
 Apache Spark An Introduction To Spark Data Mechanics
Apache Spark An Introduction To Spark Data Mechanics
 How To Install Apache Spark On Windows 10
How To Install Apache Spark On Windows 10
Apache Spark A Conceptual Orientation By Alexander Shropshire Towards Data Science
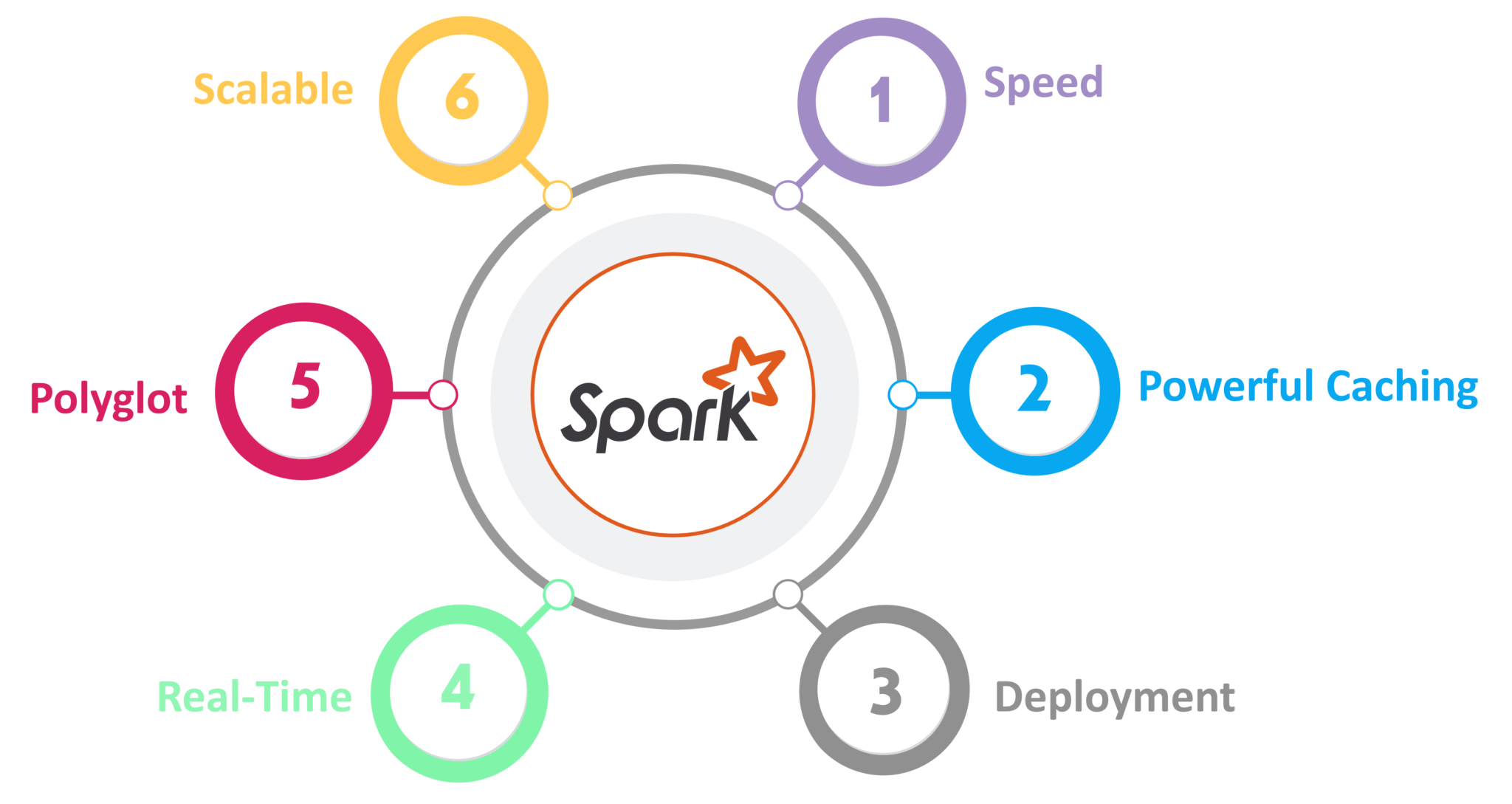
 Features Of Apache Spark Learn The Benefits Of Using Spark Dataflair
Features Of Apache Spark Learn The Benefits Of Using Spark Dataflair
 Apache Spark Perangkat Lunak Analisis Terpadu Untuk Big Data
Apache Spark Perangkat Lunak Analisis Terpadu Untuk Big Data
 Apache Spark What Is Spark
Apache Spark What Is Spark
 Apache Spark Architecture And Use Cases Overview Xenonstack
Apache Spark Architecture And Use Cases Overview Xenonstack
What Is Spark Apache Spark Tutorial For Beginners Dataflair
 What Is Apache Spark How Apache Spark Works Spark Engine
What Is Apache Spark How Apache Spark Works Spark Engine
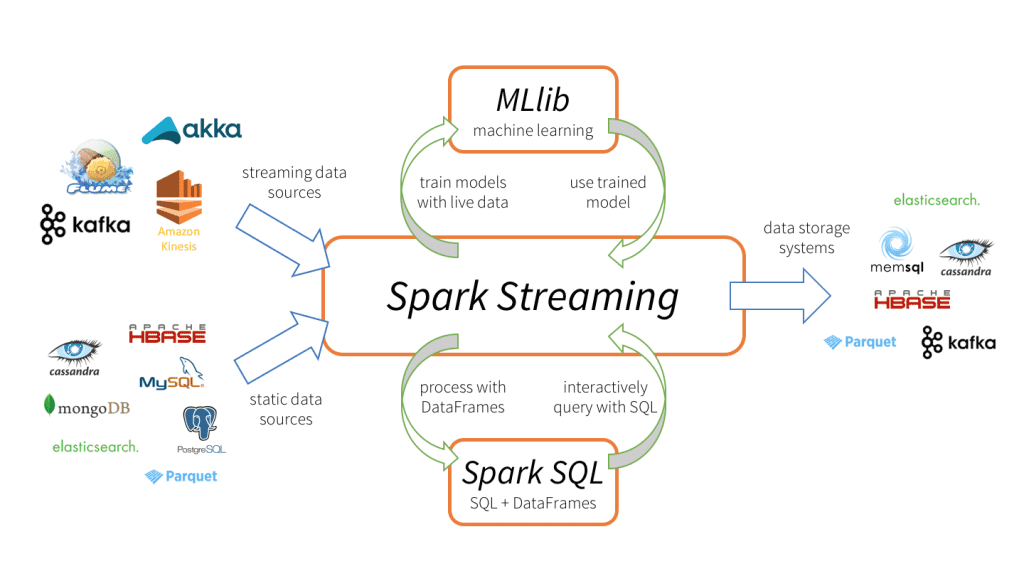 What Is Spark Streaming Databricks
What Is Spark Streaming Databricks
 Apache Spark Instaclustr
Apache Spark Instaclustr
 What Is Apache Spark Working Advantages Scope Skills
What Is Apache Spark Working Advantages Scope Skills
 What Is Apache Spark Introduction To Apache Spark And Analytics Aws
What Is Apache Spark Introduction To Apache Spark And Analytics Aws




No comments:
Post a Comment
Note: only a member of this blog may post a comment.